




































들어가며: 매번 연결을 새로 맺는 것이 왜 문제인가
JDBC로 데이터베이스를 다루는 코드를 처음 작성하면 자연스럽게 이런 패턴이 반복된다.
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
// SQL 실행
conn.close();
요청이 들어올 때마다 Connection을 새로 열고, 작업이 끝나면 닫는 방식이다. 기능적으로는 문제없이 동작하기 때문에 처음에는 이 방식이 자연스럽게 느껴진다. 그런데 이 코드에는 겉으로 드러나지 않는 비용이 숨어 있다.
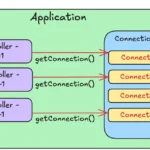
데이터베이스 Connection을 새로 맺는 과정은 생각보다 무거운 작업이다. 네트워크를 통한 TCP 소켓 연결, 사용자 인증, 세션 초기화 등 여러 단계를 거쳐야 하기 때문에, Connection 하나를 여는 데만 수십에서 수백 밀리초가 소요될 수 있다. 사용자가 한 명일 때는 체감하기 어렵다. 그러나 동시 요청이 수십 개, 수백 개로 늘어나는 순간 이 비용은 눈에 띄는 성능 저하로 이어진다.
이 문제를 해결하는 것이 커넥션 풀(Connection Pool) 이다. 이 글에서는 커넥션 풀이 왜 필요한지, 내부적으로 어떻게 동작하는지, Java에서 가장 널리 사용되는 HikariCP를 활용해 실제로 어떻게 적용하는지를 입문자도 이해할 수 있도록 단계별로 설명한다.
커넥션 풀이란 무엇인가 — 비유로 먼저 이해하기
커넥션 풀을 처음 접하는 사람에게 가장 쉽게 설명하는 방법은 비유다.
택시를 생각해보자. 매번 목적지에 갈 때마다 앱을 열고 택시를 배차받는 방식이 있고, 회사 전용 차량 여러 대를 주차장에 대기시켜두고 필요할 때 바로 꺼내 쓰는 방식이 있다. 택시는 배차 시간이 매번 발생하지만, 대기 중인 전용 차량은 즉시 탈 수 있다.
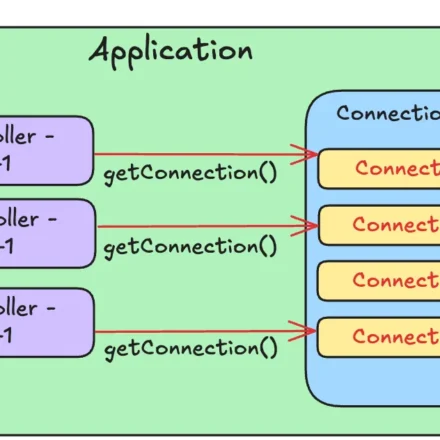
커넥션 풀은 이 “대기 중인 전용 차량”과 같다. Connection을 미리 여러 개 만들어 풀(Pool)에 보관해두고, 요청이 들어오면 풀에서 하나를 꺼내 사용하고, 작업이 끝나면 닫는 것이 아니라 다시 풀에 반납한다.
커넥션 풀의 동작 방식을 순서로 정리하면:
- 애플리케이션이 시작될 때 설정된 수만큼 Connection을 미리 생성해 풀에 보관한다.
- 요청이 들어오면 풀에서 사용 가능한 Connection을 하나 꺼낸다.
- SQL 실행이 끝나면 Connection을 닫는 것이 아니라 풀에 반납한다.
- 풀의 모든 Connection이 사용 중인 상태에서 새 요청이 들어오면, Connection이 반납될 때까지 잠시 대기한다.
이 구조 덕분에 Connection 생성 비용은 애플리케이션 시작 시 딱 한 번만 발생하고, 이후 모든 요청은 이미 만들어진 Connection을 재사용한다. 데이터베이스 연결 비용이 사라지는 것이다.
커넥션 풀 없이 작성하면 어떤 문제가 생기나
커넥션 풀의 필요성을 체감하려면 풀 없이 작성한 코드의 한계를 직접 확인하는 것이 가장 좋다.
매번 Connection을 새로 여는 방식:
public class UserDao {
private static final String URL = "jdbc:mysql://localhost:3306/testdb";
private static final String USER = "myuser";
private static final String PASSWORD = "password";
public User findById(int id) throws SQLException {
// 이 메서드가 호출될 때마다 새로운 Connection이 생성됨
try (Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(
"SELECT id, name, email FROM users WHERE id = ?")) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return new User(
rs.getInt("id"),
rs.getString("name"),
rs.getString("email")
);
}
}
}
return null;
}
}이 코드는 findById()가 호출될 때마다 새로운 Connection을 생성하고 닫는다. 사용자 한 명이 호출하면 문제없다. 그러나 100명이 동시에 이 메서드를 호출하면 100개의 Connection이 동시에 생성된다. Connection 하나를 여는 데 50ms가 걸린다고 가정하면 이 과정에만 상당한 지연이 발생한다.
더 심각한 문제는 데이터베이스 서버가 허용하는 최대 Connection 수를 초과하는 경우다. 데이터베이스 서버는 동시에 처리할 수 있는 Connection 수에 한계가 있는데, 이를 초과하면 새 Connection 요청 자체가 실패한다. 실제 서비스 환경에서 이 상황은 곧 장애로 이어진다.
HikariCP 적용하기 — 설정부터 사용까지
Java 생태계에서 현재 가장 널리 사용되는 커넥션 풀 라이브러리는 HikariCP다. 빠른 성능과 안정성으로 Spring Boot의 기본 커넥션 풀로 채택되어 있으며, 설정 방식도 간결하다.
의존성 추가 (Maven 기준):
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.1.0</version>
</dependency>
HikariCP DataSource 설정:
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import javax.sql.DataSource;
public class DatabaseConfig {
private static final HikariDataSource dataSource;
static {
HikariConfig config = new HikariConfig();
// 기본 연결 정보
config.setJdbcUrl("jdbc:mysql://localhost:3306/testdb?useSSL=false&serverTimezone=Asia/Seoul");
config.setUsername("myuser");
config.setPassword("password");
// 풀 크기 설정
config.setMaximumPoolSize(10); // 최대 Connection 수
config.setMinimumIdle(5); // 최소 유휴 Connection 수
config.setConnectionTimeout(30000); // Connection 획득 대기 시간 (30초)
config.setIdleTimeout(600000); // 유휴 Connection 유지 시간 (10분)
config.setMaxLifetime(1800000); // Connection 최대 수명 (30분)
config.setPoolName("AppConnectionPool"); // 풀 이름 (로그 식별용)
dataSource = new HikariDataSource(config);
}
// 외부에서 DataSource를 가져갈 때 사용
public static DataSource getDataSource() {
return dataSource;
}
}
static 블록 안에서 DataSource를 초기화하는 이유는, 애플리케이션 실행 중 단 한 번만 생성되어야 하기 때문이다. 매번 새로 만들면 커넥션 풀의 의미가 없어진다.
커넥션 풀을 통한 실제 사용:
public class UserDao {
public User findById(int id) throws SQLException {
String sql = "SELECT id, name, email FROM users WHERE id = ?";
// DriverManager 대신 DataSource에서 Connection을 가져온다
try (Connection conn = DatabaseConfig.getDataSource().getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return new User(
rs.getInt("id"),
rs.getString("name"),
rs.getString("email")
);
}
}
}
// conn.close() 호출 시 Connection이 실제로 닫히지 않고 풀에 반납됨
return null;
}
public void insertUser(User user) throws SQLException {
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
try (Connection conn = DatabaseConfig.getDataSource().getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, user.getName());
pstmt.setString(2, user.getEmail());
pstmt.executeUpdate();
}
}
}
기존 코드와 달라진 부분은 딱 한 줄이다. DriverManager.getConnection() 대신 DatabaseConfig.getDataSource().getConnection()을 사용한다. 나머지 코드 구조는 완전히 동일하다. 커넥션 풀을 도입한다고 해서 기존 SQL 실행 코드를 전부 바꿀 필요가 없다는 점이 HikariCP의 큰 장점이다.
핵심 설정값의 의미와 적정 기준
HikariCP를 처음 적용할 때 설정값의 의미를 제대로 이해하지 않으면 오히려 문제가 생길 수 있다. 자주 접하게 되는 설정값들을 하나씩 정리한다.
maximumPoolSize — 풀의 최대 Connection 수
풀에서 동시에 사용할 수 있는 Connection의 최대 개수다. 이 값을 무조건 크게 설정한다고 성능이 좋아지지는 않는다. Connection 수가 많아질수록 데이터베이스 서버의 부하도 함께 증가하기 때문이다. HikariCP 공식 문서에서는 (CPU 코어 수 × 2) + 유효 디스크 수 공식을 참고 기준으로 제시한다. 처음에는 10 정도로 시작해 서비스 모니터링 결과를 보며 조정하는 것이 현실적인 접근이다.
minimumIdle — 최소 유휴 Connection 수
풀에서 항상 유지할 최소 Connection 수다. 트래픽이 낮은 시간대에도 이 수만큼의 Connection은 열린 상태를 유지한다. HikariCP는 이 값을 maximumPoolSize와 동일하게 설정하는 것을 권장한다. Connection 수를 동적으로 조절하는 과정에서 발생하는 오버헤드를 없애기 위해서다.
connectionTimeout — Connection 획득 대기 시간
풀의 모든 Connection이 사용 중일 때 새 요청이 얼마나 기다릴 수 있는지를 밀리초 단위로 설정한다. 이 시간을 초과하면 SQLTimeoutException이 발생한다. 기본값은 30초(30,000ms)이며, 웹 서비스처럼 응답 시간이 중요한 환경에서는 5~10초로 낮추는 경우도 많다.
maxLifetime — Connection 최대 수명
Connection이 생성된 후 풀에서 유지될 수 있는 최대 시간이다. 데이터베이스 서버는 일정 시간 동안 사용되지 않은 Connection을 서버 측에서 강제로 끊어버리는 경우가 있다. 이런 상황에서 풀이 이미 끊어진 Connection을 재사용하려 하면 오류가 발생한다. maxLifetime을 설정하면 Connection을 주기적으로 교체해 이 문제를 예방할 수 있다. 데이터베이스 서버의 wait_timeout 설정보다 몇 초 짧게 설정하는 것이 일반적인 기준이다.
idleTimeout — 유휴 Connection 유지 시간
풀에서 아무 작업 없이 대기 중인 Connection을 얼마나 유지할지를 설정한다. 이 시간이 지난 유휴 Connection은 풀에서 제거된다. minimumIdle로 설정한 최소 수 이하로는 줄어들지 않는다.
커넥션 풀 사용 시 자주 발생하는 실수 3가지
커넥션 풀을 처음 도입할 때 반복적으로 발생하는 실수들이 있다. 미리 알아두면 불필요한 디버깅 시간을 줄일 수 있다.
실수 1: Connection을 반납하지 않는 경우
conn.close()를 호출하지 않으면 Connection이 풀로 반납되지 않는다. 이 상태가 반복되면 풀의 Connection이 모두 소진되고, 새 요청은 connectionTimeout까지 대기하다 예외를 던진다. try-with-resources 구문을 사용하면 블록이 끝날 때 자동으로 close()가 호출되므로 이 문제를 확실히 예방할 수 있다.
// 잘못된 방식 — close()를 직접 호출해야 하는데 예외 발생 시 누락될 수 있음
Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.executeUpdate();
conn.close(); // 예외 발생 시 이 줄이 실행되지 않을 수 있음
// 올바른 방식 — try-with-resources로 자동 반납 보장
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.executeUpdate();
} // 블록 종료 시 자동으로 close() 호출 → 풀에 반납
실수 2: maximumPoolSize를 지나치게 크게 설정하는 경우
Connection 수를 늘리면 성능이 무조건 좋아질 것이라는 오해가 있다. 실제로는 Connection 수가 일정 수준을 넘어서면 데이터베이스 서버에서 처리해야 할 동시 세션이 많아져 오히려 전체 처리 속도가 느려진다. 10~20 수준에서 시작해 서비스 상황을 보며 조정하는 것이 바람직하다.
실수 3: DataSource를 매번 새로 생성하는 경우
DataSource는 반드시 애플리케이션 전체에서 하나의 인스턴스만 존재해야 한다. 메서드가 호출될 때마다 new HikariDataSource(config)를 실행하면 매번 새로운 풀이 생성되어 커넥션 풀의 효과가 완전히 사라진다. 싱글턴 패턴을 사용하거나 Spring을 사용하는 경우 @Bean으로 등록해 하나의 인스턴스가 공유되도록 해야 한다.
// 잘못된 방식 — 호출될 때마다 새 풀 생성
public DataSource createDataSource() {
HikariConfig config = new HikariConfig();
// 설정...
return new HikariDataSource(config); // 매번 새로운 풀이 만들어짐
}
// 올바른 방식 — static 또는 싱글턴으로 한 번만 생성
private static final HikariDataSource dataSource;
static {
HikariConfig config = new HikariConfig();
// 설정...
dataSource = new HikariDataSource(config); // 한 번만 생성
}Spring Boot에서는 어떻게 사용하나
지금까지는 순수 Java 환경에서 HikariCP를 직접 설정하는 방법을 다뤘다. 실무에서 Spring Boot를 사용하는 경우에는 훨씬 간단하다. spring-boot-starter-jdbc 또는 spring-boot-starter-data-jpa 의존성을 추가하면 HikariCP가 자동으로 포함되고, application.yml 설정만으로 풀 옵션을 제어할 수 있다.
Spring Boot application.yml 설정 예시:
spring:
datasource:
url: jdbc:mysql://localhost:3306/testdb?useSSL=false&serverTimezone=Asia/Seoul
username: myuser
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 10
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
pool-name: SpringAppPool
Spring Boot에서 DataSource 주입받아 사용:
import org.springframework.stereotype.Repository;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@Repository
public class UserDao {
private final DataSource dataSource;
// Spring이 자동으로 HikariCP DataSource를 주입해준다
public UserDao(DataSource dataSource) {
this.dataSource = dataSource;
}
public User findById(int id) throws SQLException {
String sql = "SELECT id, name, email FROM users WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return new User(
rs.getInt("id"),
rs.getString("name"),
rs.getString("email")
);
}
}
}
return null;
}
}
Spring Boot 환경에서는 DatabaseConfig 클래스를 직접 만들 필요 없이, application.yml 설정만으로 HikariCP가 자동으로 구성된다. 코드에서는 DataSource를 주입받아 사용하기만 하면 된다.
나오며: 커넥션 풀은 선택이 아니라 기본이다
커넥션 풀은 실제 서비스 환경에서 JDBC를 사용하는 모든 Java 애플리케이션에 반드시 적용해야 하는 기본 설정이다. 개발 환경에서는 요청이 적어 문제가 드러나지 않지만, 트래픽이 증가하는 순간 커넥션 풀 없이 작성된 코드는 즉각적인 성능 저하와 장애로 이어진다.
이번 글에서 다룬 내용을 정리하면 다음과 같다.
| 개념 | 핵심 내용 |
|---|---|
| 커넥션 풀 | Connection을 미리 만들어 재사용하는 방식 |
| HikariCP | Java에서 가장 널리 사용되는 커넥션 풀 라이브러리 |
| maximumPoolSize | 최대 Connection 수, 크다고 좋은 것이 아님 |
| connectionTimeout | 풀이 꽉 찼을 때 대기 허용 시간 |
| try-with-resources | Connection 자동 반납을 보장하는 필수 패턴 |
| DataSource 싱글턴 | 애플리케이션 전체에서 하나의 인스턴스만 유지 |
JDBC → 트랜잭션 → 커넥션 풀까지 이해했다면, 이후 학습할 MyBatis나 Spring Data JPA가 이 세 가지 개념 위에서 어떻게 동작하는지가 훨씬 명확하게 보일 것이다. 다음 단계로는 MyBatis와 HikariCP 연동 또는 Spring Boot에서의 트랜잭션 관리(@Transactional) 를 학습하는 것을 권장한다.






Add your first comment to this post