




































들어가며: 흩어진 개념을 하나의 선으로 연결하기
Java로 백엔드 개발을 공부하다 보면 JDBC, PreparedStatement, 트랜잭션, 커넥션 풀, MyBatis 같은 개념들을 각각 따로 배우게 되는 경우가 많다. 하나씩 배울 때는 이해가 됐는데, 막상 전체 그림을 그리려고 하면 “이게 어디에 쓰이는 건지”, “왜 이 순서로 발전해온 건지”가 명확하지 않게 느껴지는 경험이 있을 것이다.
이 글은 그 흩어진 개념들을 하나의 흐름으로 연결하는 것이 목적이다. JDBC가 무엇인지부터 시작해서, CRUD 구현, 트랜잭션 처리, 커넥션 풀 도입, 그리고 MyBatis까지 이어지는 Java DB 처리 흐름을 각 단계가 왜 등장했는지와 함께 압축 정리한다. 각 주제를 더 깊이 공부하고 싶다면 섹션마다 연결된 상세 글을 참고하면 된다.
JDBC — Java와 데이터베이스를 연결하는 표준 통로
Java 애플리케이션이 데이터베이스와 통신하려면 중간 다리가 필요하다. 그 역할을 하는 것이 JDBC(Java Database Connectivity) 다. JDBC는 Java 표준 API로, MySQL이든 Oracle이든 PostgreSQL이든 동일한 방식으로 데이터베이스에 접근할 수 있게 해준다.
JDBC를 사용한 기본 연결 구조는 다음과 같다.
// 1. 데이터베이스 연결
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/testdb", "myuser", "password"
);
// 2. SQL 준비
PreparedStatement pstmt = conn.prepareStatement(
"SELECT id, name FROM users WHERE id = ?"
);
pstmt.setInt(1, 1);
// 3. 실행 및 결과 처리
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println(rs.getString("name"));
}
// 4. 자원 종료
rs.close();
pstmt.close();
conn.close();
이 흐름은 연결 → SQL 준비 → 실행 → 결과 처리 → 종료 다섯 단계로 구성된다. JDBC를 통한 모든 데이터베이스 작업은 이 구조를 기반으로 동작한다.
여기서 중요한 것은 PreparedStatement를 사용하는 이유다. SQL 문자열에 값을 직접 이어 붙이는 Statement 방식은 SQL Injection 공격에 취약하다. PreparedStatement는 SQL과 데이터를 분리해서 전달하기 때문에 이 문제를 원천 차단한다. 실무에서는 반드시 PreparedStatement를 사용하는 것이 기본 원칙이다.
CRUD — 데이터를 다루는 네 가지 기본 동작
데이터베이스를 다루는 모든 애플리케이션은 결국 네 가지 동작의 조합으로 이루어진다. 생성(Create), 조회(Read), 수정(Update), 삭제(Delete). 이것이 CRUD다.
회원가입은 INSERT, 로그인 시 사용자 정보 조회는 SELECT, 프로필 수정은 UPDATE, 회원 탈퇴는 DELETE로 처리된다. 우리가 매일 사용하는 모든 서비스가 이 네 가지의 조합으로 동작한다.
JDBC에서 INSERT, UPDATE, DELETE는 모두 executeUpdate()를 사용하고, SELECT는 executeQuery()를 사용한다는 점이 핵심 차이다.
// INSERT — executeUpdate() 사용, 반환값은 영향받은 행 수
String insertSql = "INSERT INTO users (name, email) VALUES (?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(insertSql)) {
pstmt.setString(1, "홍길동");
pstmt.setString(2, "hong@example.com");
int result = pstmt.executeUpdate(); // 성공 시 1 반환
}
// UPDATE — WHERE 조건 필수, 없으면 전체 데이터 변경
String updateSql = "UPDATE users SET email = ? WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(updateSql)) {
pstmt.setString(1, "new@example.com");
pstmt.setInt(2, 1);
pstmt.executeUpdate();
}
// DELETE — WHERE 조건 필수, 없으면 전체 데이터 삭제
String deleteSql = "DELETE FROM users WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(deleteSql)) {
pstmt.setInt(1, 1);
pstmt.executeUpdate();
}
UPDATE와 DELETE에서 WHERE 조건은 선택이 아니라 필수다. 조건을 빠뜨리면 테이블의 모든 데이터가 변경되거나 삭제된다. 실무에서 가장 자주 발생하는 치명적인 실수 중 하나다.
CRUD 전체 내용은 아래 글에서 더 자세히 확인할 수 있다.

트랜잭션 — 여러 작업을 하나로 묶는 방법
CRUD를 이해했다면 다음 질문이 자연스럽게 따라온다. “주문 생성과 재고 감소를 함께 처리해야 하는데, 주문은 됐는데 재고 감소가 실패하면 어떻게 되지?” 이 문제를 해결하는 것이 트랜잭션이다.
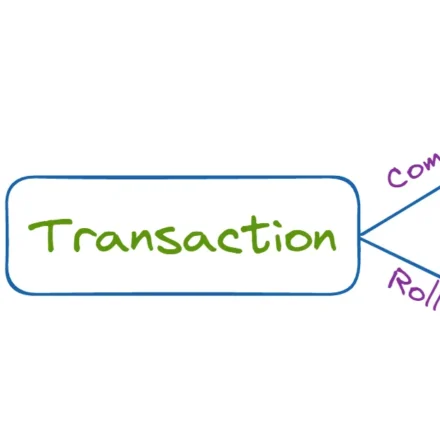
트랜잭션은 여러 개의 데이터베이스 작업을 하나의 단위로 묶어, 전부 성공하거나 전부 실패하도록 보장한다.
JDBC에서 트랜잭션을 직접 제어하는 기본 패턴은 다음과 같다.
Connection conn = null;
try {
conn = DriverManager.getConnection(URL, USER, PASSWORD);
conn.setAutoCommit(false); // 자동 커밋 비활성화 → 트랜잭션 시작
// 작업 1: 주문 생성
String insertSql = "INSERT INTO orders (user_id, product_id, quantity) VALUES (?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(insertSql)) {
pstmt.setInt(1, 1);
pstmt.setInt(2, 10);
pstmt.setInt(3, 2);
pstmt.executeUpdate();
}
// 작업 2: 재고 감소
String updateSql = "UPDATE products SET stock = stock - ? WHERE id = ? AND stock >= ?";
try (PreparedStatement pstmt = conn.prepareStatement(updateSql)) {
pstmt.setInt(1, 2);
pstmt.setInt(2, 10);
pstmt.setInt(3, 2);
int updated = pstmt.executeUpdate();
if (updated == 0) {
throw new IllegalStateException("재고 부족");
}
}
conn.commit(); // 두 작업 모두 성공 시 확정
} catch (Exception e) {
if (conn != null) conn.rollback(); // 하나라도 실패 시 전체 취소
} finally {
if (conn != null) {
conn.setAutoCommit(true);
conn.close();
}
}
setAutoCommit(false)로 자동 커밋을 끄고, 모든 작업이 성공하면 commit(), 하나라도 실패하면 rollback()을 호출하는 구조다. finally 블록에서 반드시 setAutoCommit(true)로 복원해야 한다는 점도 중요하다. 커넥션 풀 환경에서 이를 빠뜨리면 반납된 Connection이 다음 요청에서 오작동할 수 있다.
트랜잭션 처리 전체 내용은 아래 글에서 더 자세히 확인할 수 있다.

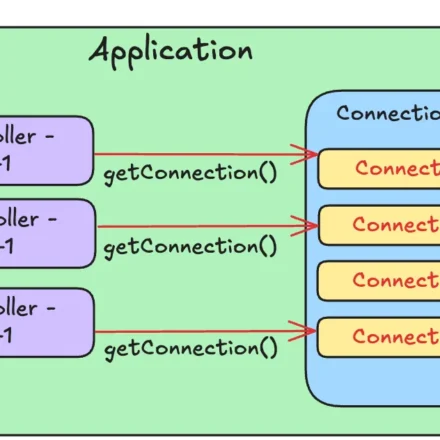
커넥션 풀 — 연결 비용을 없애는 방법
JDBC로 작업을 하다 보면 요청마다 DriverManager.getConnection()으로 새 Connection을 열게 된다. 그런데 Connection 하나를 여는 데는 TCP 연결, 인증, 세션 초기화 등 상당한 비용이 든다. 사용자가 한 명일 때는 문제없지만, 동시 요청이 수백 개로 늘어나면 이 비용이 성능 병목으로 직결된다.
커넥션 풀(Connection Pool) 은 Connection을 미리 여러 개 만들어두고, 요청이 들어오면 풀에서 꺼내 쓰고, 작업이 끝나면 풀에 반납하는 방식이다. Connection 생성 비용이 애플리케이션 시작 시 한 번만 발생하고, 이후 모든 요청은 이미 만들어진 Connection을 재사용한다.
Java에서 가장 널리 쓰이는 커넥션 풀 라이브러리는 HikariCP다. Spring Boot의 기본 커넥션 풀로 채택될 만큼 성능과 안정성이 검증되어 있다.
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/testdb?useSSL=false&serverTimezone=Asia/Seoul");
config.setUsername("myuser");
config.setPassword("password");
config.setMaximumPoolSize(10); // 최대 Connection 수
config.setMinimumIdle(5); // 최소 유휴 Connection 수
config.setConnectionTimeout(30000); // 대기 허용 시간 (30초)
config.setMaxLifetime(1800000); // Connection 최대 수명 (30분)
HikariDataSource dataSource = new HikariDataSource(config);
기존 코드에서 DriverManager.getConnection() 대신 dataSource.getConnection()으로 교체하기만 하면 된다. conn.close()를 호출해도 실제로 닫히는 것이 아니라 풀에 반납된다.
커넥션 풀 전체 내용은 아래 작성 된 글에서 더 자세히 확인할 수 있다.

MyBatis — JDBC의 반복을 없애는 SQL Mapper
JDBC로 CRUD, 트랜잭션, 커넥션 풀까지 구현해보면 한 가지 불편함이 쌓인다. 매번 Connection을 가져오고, PreparedStatement를 생성하고, 파라미터를 바인딩하고, ResultSet을 객체로 변환하는 코드가 모든 DAO 메서드에 반복된다. 쿼리가 10개면 이 반복 코드도 10개다.
MyBatis는 이 반복을 없애주는 SQL Mapper 프레임워크다. SQL은 개발자가 직접 작성하되, Connection 관리·파라미터 바인딩·ResultSet 변환 같은 반복 작업은 프레임워크가 자동으로 처리한다.
MyBatis를 사용하면 SQL은 XML 파일에 정의하고, Java 코드에서는 인터페이스 메서드 호출만으로 SQL을 실행할 수 있다.
Mapper XML (UserMapper.xml):
<mapper namespace="com.example.mapper.UserMapper">
<select id="findById" parameterType="int" resultType="User">
SELECT id, name, email
FROM users
WHERE id = #{id}
</select>
<insert id="insertUser" parameterType="User">
INSERT INTO users (name, email)
VALUES (#{name}, #{email})
</insert>
<update id="updateUser" parameterType="User">
UPDATE users
SET email = #{email}
WHERE id = #{id}
</update>
<delete id="deleteUser" parameterType="int">
DELETE FROM users WHERE id = #{id}
</delete>
</mapper>
Mapper 인터페이스:
public interface UserMapper {
User findById(int id);
void insertUser(User user);
void updateUser(User user);
void deleteUser(int id);
}
실제 호출:
try (SqlSession session = sqlSessionFactory.openSession()) {
UserMapper mapper = session.getMapper(UserMapper.class);
// 조회
User user = mapper.findById(1);
// 등록
mapper.insertUser(new User("이순신", "lee@example.com"));
session.commit();
}
JDBC와 비교했을 때 가장 큰 차이는 두 가지다. 첫째, Connection 열기·닫기·파라미터 바인딩·ResultSet 처리 코드가 완전히 사라졌다. 둘째, 문자열 기반 쿼리 호출이 아닌 인터페이스 메서드 호출이기 때문에 오타가 컴파일 단계에서 잡힌다.
MyBatis 전체 내용은 아래글에서 더 자세히 확인할 수 있다.

전체 흐름 한눈에 보기 — 기술이 발전해온 이유
지금까지 다룬 내용을 하나의 흐름으로 정리하면 다음과 같다.
JDBC (기초) └─ Java와 DB를 연결하는 표준 API └─ PreparedStatement로 SQL Injection 방지 CRUD (데이터 처리) └─ INSERT / SELECT / UPDATE / DELETE └─ executeUpdate vs executeQuery 구분 트랜잭션 (데이터 정합성) └─ 여러 작업을 하나로 묶어 전부 성공 또는 전부 실패 └─ setAutoCommit → commit / rollback 커넥션 풀 (성능) └─ Connection을 미리 만들어 재사용 └─ HikariCP로 손쉽게 적용 MyBatis (생산성) └─ JDBC 반복 코드를 프레임워크가 처리 └─ SQL은 직접 작성, 나머지는 자동화
각 기술이 등장한 이유는 명확하다. JDBC만으로는 반복 코드가 많고 실수가 발생하기 쉬웠고, 트랜잭션을 빠뜨리면 데이터 정합성이 깨졌으며, 요청마다 Connection을 새로 열면 성능이 나빠졌다. 각각의 문제를 해결하기 위해 다음 단계 기술이 등장했고, 그 흐름이 지금의 기술 스택으로 이어졌다.
어떤 기술을 선택해야 하는가에 대한 기준:
| 상황 | 권장 기술 |
|---|---|
| 학습 목적, DB 연동 원리 이해 | 순수 JDBC |
| SQL 직접 제어가 중요한 실무 프로젝트 | MyBatis |
| 도메인 모델 중심 설계, 단순 CRUD 위주 | Spring Data JPA |
| 복잡한 통계 쿼리 + 일반 CRUD 혼재 | MyBatis + JPA 병행 |
기초를 이해한 사람이 프레임워크도 제대로 쓴다
MyBatis나 JPA를 처음 배울 때 “그냥 이 프레임워크 쓰는 방법만 익히면 되는 거 아닌가?”라는 생각이 들 수 있다. 하지만 JDBC의 동작 원리를 모르는 상태에서 프레임워크를 쓰다 보면, 문제가 발생했을 때 원인을 찾지 못하는 상황이 반복된다.
MyBatis도, JPA도, HikariCP도 결국 JDBC 위에서 동작한다. 프레임워크는 개발자가 직접 작성해야 했던 JDBC 코드를 대신 처리해줄 뿐이다. JDBC에서 Connection이 왜 닫혀야 하는지, 트랜잭션이 어떤 구조로 동작하는지, 커넥션 풀이 왜 필요한지를 이해한 상태에서 프레임워크를 사용하면 동작 방식이 훨씬 명확하게 보인다.
이 시리즈에서 다룬 내용을 순서대로 정리하면 다음과 같다.
| 순서 | 주제 | 링크 |
|---|---|---|
| 1 | JDBC CRUD 완전 정리 | [바로가기] |
| 2 | Java 트랜잭션 처리 | [바로가기] |
| 3 | 커넥션 풀 이해하기 | [바로가기] |
| 4 | iBatis vs MyBatis 비교 | [바로가기] |
| 5 | 전체 흐름 정리 (현재 글) | — |
다음 단계로는 Spring Boot에서의 MyBatis 연동과 Spring @Transactional을 활용한 선언적 트랜잭션 관리를 학습하는 것을 권장한다. 이 두 가지를 이해하고 나면 실무 수준의 Java 백엔드 데이터베이스 처리 흐름을 완성할 수 있다.






Add your first comment to this post